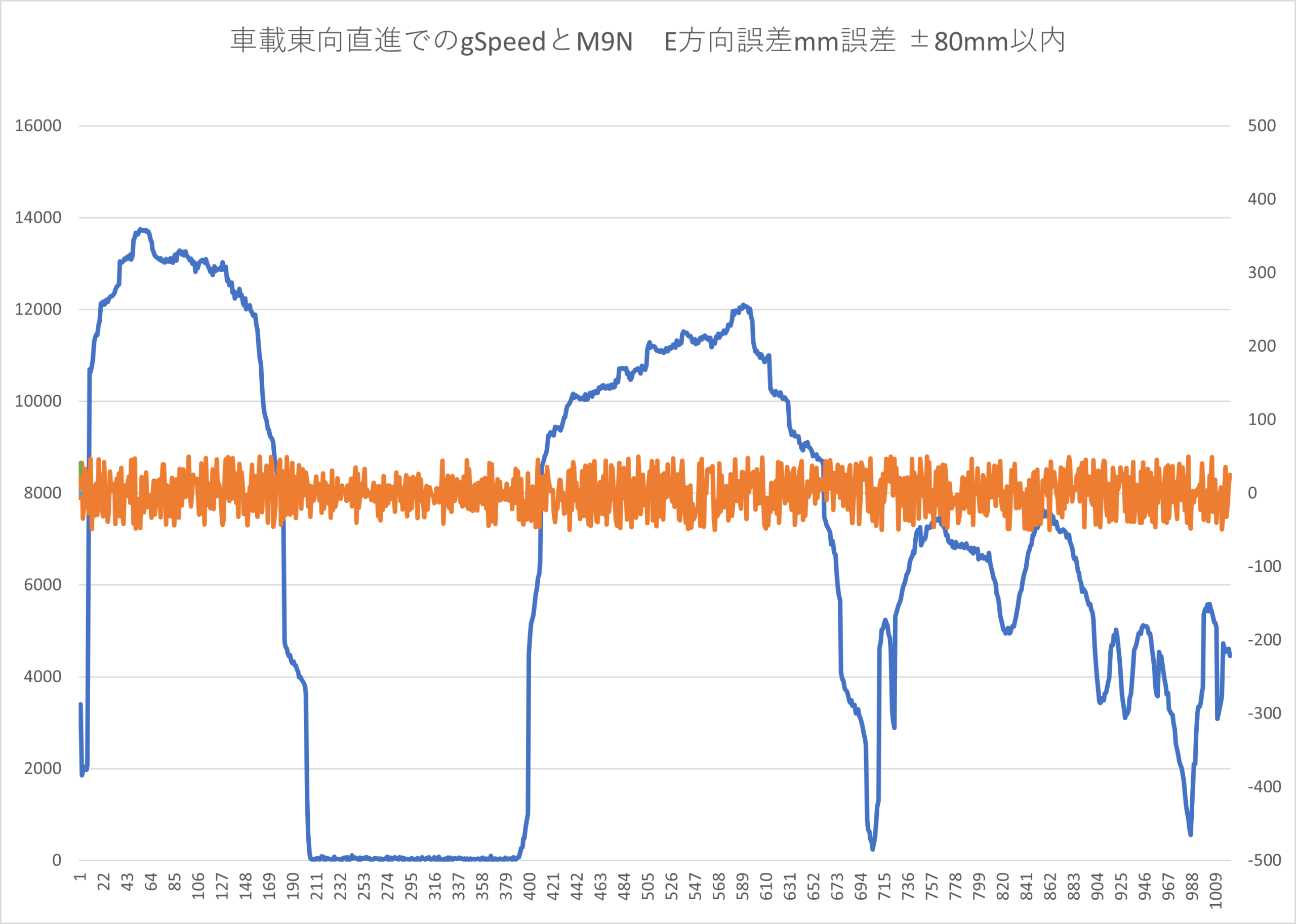
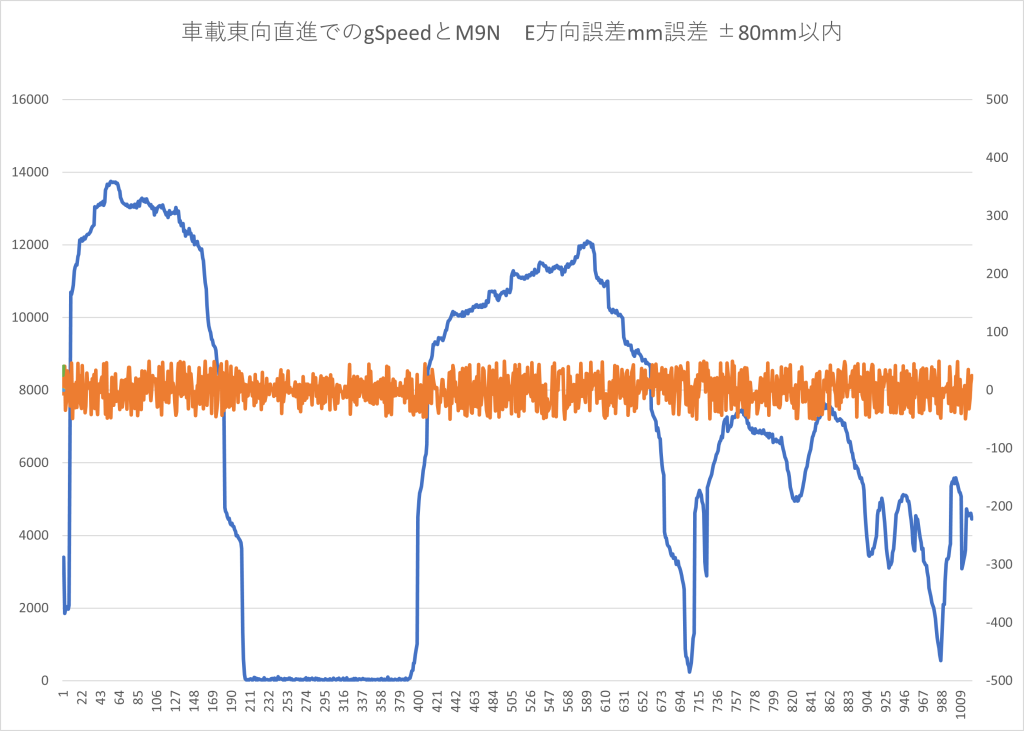
M9Nの設定がデフォルトだったので、転回運動は誤差が大きくなっていたので、直進部分を抽出して
デバッグ用のデータとしました。
データ処理の流れを備忘録します。
①データログ
M9Nは、チップアンテナ版なので、基板半分外にだしてあります、
RTKアンテナのグランドプレーン板の下にSimpleRTK2B liteを設置してます。USBシリアル変換ノジュールでUSBケーブル接続してポールの手持ち部まで引き回して、タブレットに接続します。
M9NもUSBケーブルで引き回して、タブレットへ入れます

タブレットは、corei5です。ATOMだとucenter2個起動は厳しいのでcorei5の大き目のタブレットにしました。
②ログデータをパース(構文解析)
ubxメッセージは、バイナリの一連のデータですが、これを実数値に変換しないとデータ見れません。これが中々大変な作業で、過去に何度もハマってます。今回は、ChatGPTにコードをつくらせましたが、仕様書を見て一から解読するという作業をなかなかやってくれません。ライブラリにpyubx2というのがあるのですが
私のような高精度値には対応してないので、RELPOSNEDのHPN値はライブラリなしでバイナリから変換しないといけませんでした。ChatGPTを説得してやってもらいました。
■pyubx2ライブラリ
https://github.com/semuconsulting/pyubx2
オンラインマニュアルが
https://www.semuconsulting.com/pyubx2/py-modindex.html
今回つかったのは,メッセージ種類は、NAV-PVT,NAV-RELPOSNED ,NAV-SAT
MON-SYS,MON-VER等です。
ここで、例外的にRELPOSNEDの高精度項目HPN HPE HPDにはライブラリが対応してなかったので
バイトデータを取得して、スライスしてHPデータに変換して、0.1mm分解能まで上げてます。
|
ubr = UBXReader(fh, protfilter=UBX_PROTOCOL, parsebitfield=True)
for raw, parsed in ubr:
if parsed is None:
continue
identity = parsed.identity # e.g. ‘NAV-PVT’, ‘NAV-RELPOSNED’
# 基本フィールド辞書化
try:
fields = parsed.to_dict()
except AttributeError:
fields = {k: v for k, v in parsed.__dict__.items() if not k.startswith(‘_’)}
# NAV-RELPOSNED の場合、HP成分をrawバイナリから抽出
if identity == ‘NAV-RELPOSNED’:
# raw: バイト列(header+length+payload+checksum)
# payload offset: 6..6+length
length = struct.unpack(‘<H’, raw[4:6])[0]
payload = raw[6:6+length]
if len(payload) >= 35:
# relPosHP fields at offsets 32,33,34
relPosHPN = struct.unpack(‘<b’, payload[32:33])[0]
relPosHPE = struct.unpack(‘<b’, payload[33:34])[0]
relPosHPD = struct.unpack(‘<b’, payload[34:35])[0]
fields[‘relPosHPN’] = relPosHPN
fields[‘relPosHPE’] = relPosHPE
fields[‘relPosHPD’] = relPosHPD
# combine cm->mm
if ‘relPosN’ in fields:
fields[‘relPosN_mm’] = fields[‘relPosN’] * 10 + relPosHPN
if ‘relPosE’ in fields:
fields[‘relPosE_mm’] = fields[‘relPosE’] * 10 + relPosHPE
if ‘relPosD’ in fields:
fields[‘relPosD_mm’] = fields[‘relPosD’] * 10 + relPosHPD
# iTOWをintにしてソートしやすく
if ‘iTOW’ in fields:
fields[‘iTOW’] = int(fields[‘iTOW’])
# メッセージ毎にリストへ
msg_dict.setdefault(identity, []).append(fields)
|
このコード parse_Allubx_04.pyはGISTにおいてあります。
https://gist.github.com/dj1711572002/395c889b28a88b04c2f0fc8d0529f541
ubxファイルを読み込めばどんなメッセージ毎にCSVファイルで同じフォルダに出力してくれます。
③データ処理プログラム
パースしたCSVを読み込んで、それぞれtkinterで読み込ませます。
| 処理内容 | |
| csvをdf化 | f9pのpvt=>df_f9p,f9pのrelposned=>df_f9p_rel,m9nのpvt=>df_m9n |
| 対象範囲切取り |
299027120~299405120の範囲をExcelで事前に選んでありましたので、切り取り
df_f9p_trimmed = df_f9p[(df_f9p[‘iTOW’] >= 299027120) & (df_f9p[‘iTOW’] <= 299405120)].copy()
df_m9n_trimmed = df_m9n[(df_m9n[‘iTOW’] >= 299027120) & (df_m9n[‘iTOW’] <= 299405120)].copy()
df_f9p_rel_trimmed = df_f9p_rel[(df_f9p_rel[‘iTOW’] >= 299027120) & (df_f9p_rel[‘iTOW’] <= 299405120)].copy()
#print(df_f9p_trimmed)
|
| iTOWでソート して抜けがあればNanにする |
#iTOW sort
df_f9p_sorted=interpolate_by_iTOW(df_f9p_trimmed, itow_col=’iTOW’, interval_ms=120)
df_f9p_rel_sorted=interpolate_by_iTOW(df_f9p_rel_trimmed, itow_col=’iTOW’, interval_ms=120)
df_m9n_sorted=interpolate_by_iTOW(df_m9n_trimmed, itow_col=’iTOW’, interval_ms=40)
|
| iTOWが整っているかチェック |
# f9p iTOW sorted check
is_ok, diff_freq = check_itow_diff(df_f9p_sorted, itow_col=’iTOW’, expected_diff=120)
if is_ok:
print(“✅ f9p iTOW間隔はすべて120msで揃っています。”)
else:
print(“❌ f9p iTOW間隔に不一致があります。出現頻度:”)
print(diff_freq)
# f9p_rel iTOW sorted check
is_ok, diff_freq = check_itow_diff(df_f9p_rel_sorted, itow_col=’iTOW’, expected_diff=120)
if is_ok:
print(“✅ f9p_rel iTOW間隔はすべて120msで揃っています。”)
else:
print(“❌ f9p_rerl iTOW間隔に不一致があります。出現頻度:”)
print(diff_freq)
|
| ソートファイル を保存 |
out_file_f9p = os.path.join(os.path.dirname(f9p_file), f”{base}_sorted_f9p.csv”) out_file_f9p_rel = os.path.join(os.path.dirname(f9p_file_rel), f”{base}_sorted_f9p_rel.csv”) out_file_m9n = os.path.join(os.path.dirname(m9n_file), f”{base}_sorted_m9n.csv”) |
| M9Nの積分 |
積分値dN dE
df_integrated = integrate_and_compare_blocks(df_m9n, df_f9p_rel)
内容:台形積分 # 台形則での距離 [mm] 計算
# velN/E は cm/s → cm → mm なので *10
seg[‘vN_prev’] = seg[‘velN’].shift(1).fillna(seg[‘velN’])
seg[‘vE_prev’] = seg[‘velE’].shift(1).fillna(seg[‘velE’])
seg[‘dN_mm’] = (seg[‘vN_prev’] + seg[‘velN’]) * 0.5 * seg[‘dt_s’]
seg[‘dE_mm’] = (seg[‘vE_prev’] + seg[‘velE’]) * 0.5 * seg[‘dt_s’]
# 累積
seg[‘cN’] = seg[‘dN_mm’].cumsum()
seg[‘cE’] = seg[‘dE_mm’].cumsum()
出力: records.append({
‘block_id’: block_id,
‘start_iTOW’: start,
‘end_iTOW’: end,
‘velN0’: velN0, ‘velN1’: velN1, ‘velN2’: velN2, ‘velN3’: velN3,
‘velE0’: velE0, ‘velE1’: velE1, ‘velE2’: velE2, ‘velE3’: velE3,
‘gSpeed’: float(end_row[gSpeed_col]),
‘headMot’: float(end_row[headMot_col]),
‘dN0_mm’: dN0, ‘dN1_mm’: dN1, ‘dN2_mm’: dN2,
‘dE0_mm’: dE0, ‘dE1_mm’: dE1, ‘dE2_mm’: dE2,
‘rel_dN_mm’: rel_dN, ‘rel_dE_mm’: rel_dE,
‘errN_mm’: errN, ‘errE_mm’: errE, ‘err3d_mm’: err3d,
‘relPosN_mm’: float(r1[relN_mm_col].iloc[0]),
‘relPosE_mm’: float(r1[relE_mm_col].iloc[0])
})
|
|
|
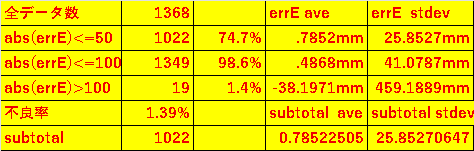
●データ結果
F9Pのエポック内で積分した結果とF9PのrelPos値との差をerrN errEで何mm誤差があるかを出力します
Excel ファイル ●●80mmM9N積分誤差解析01_@COM7___115200_250702_105847_nav_pvt_v04_Integrated_m9n
統計値をみると
全1268データ中100mm以上の誤差は1.39%で除外してもよいです。
100mm以内が1349個あって98.6%でerrE stdev41mmで2σで82mm
50mm以内が1022個あって74.7%でerrE25.85mmで2σで51mmでした。