
pythonでデータ処理プログラム1か月かけてようやくver0.1が完成しました。主にpandas を使ったので、pandasのTips備忘録して
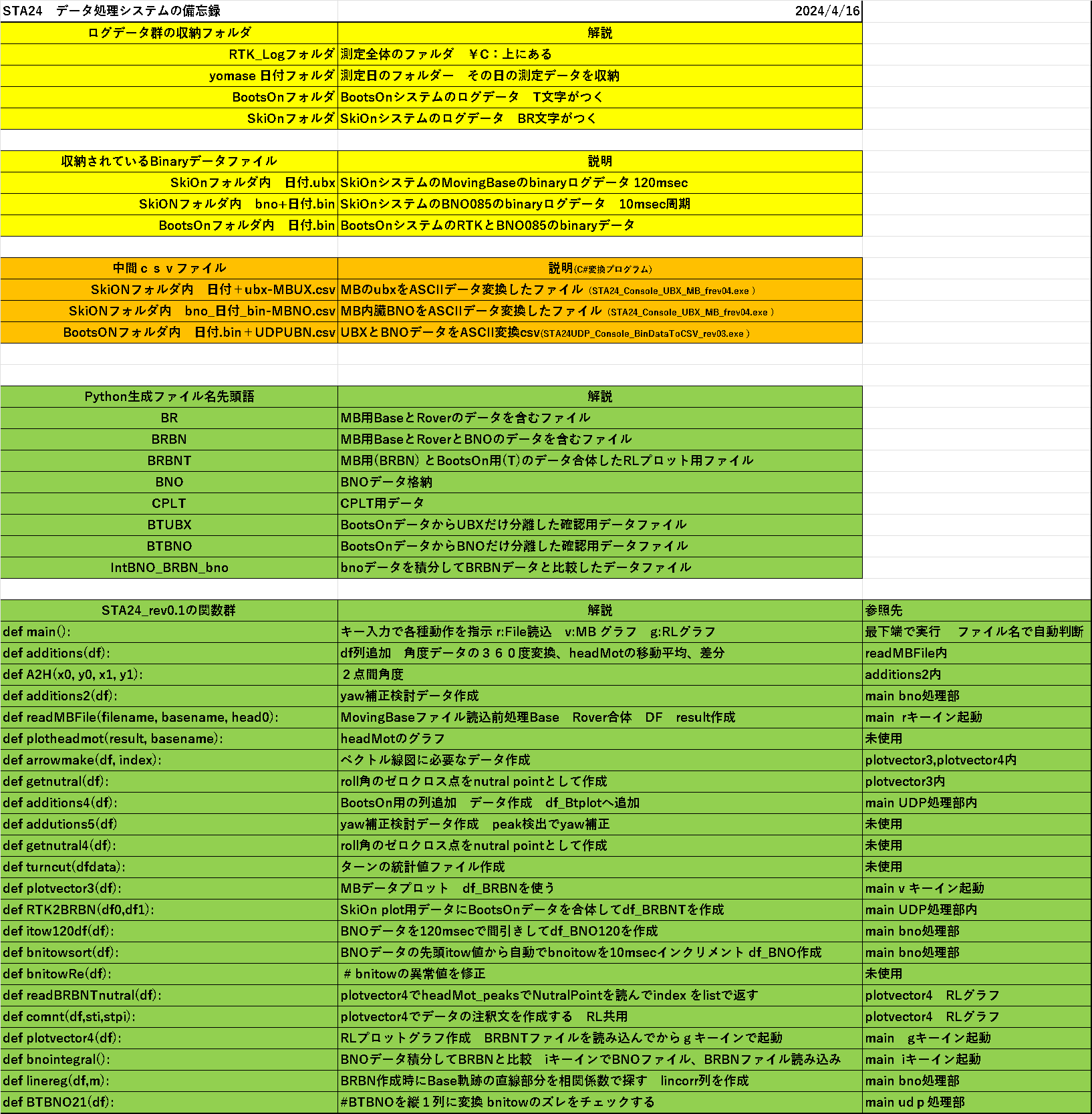
STA24データ処理システム全体の備忘録も残しておきます。
pythonコードはGISTにおいてあります。
https://gist.github.com/dj1711572002/b6d6e114a4e19128115f3b8466a0148e
●STA24データ処理システムの特徴
RTKとBNO085の全データを1個でも逃さずモニターできるようにしました。RTKとIMUのデータの同期と互いの補間もいれてあります。
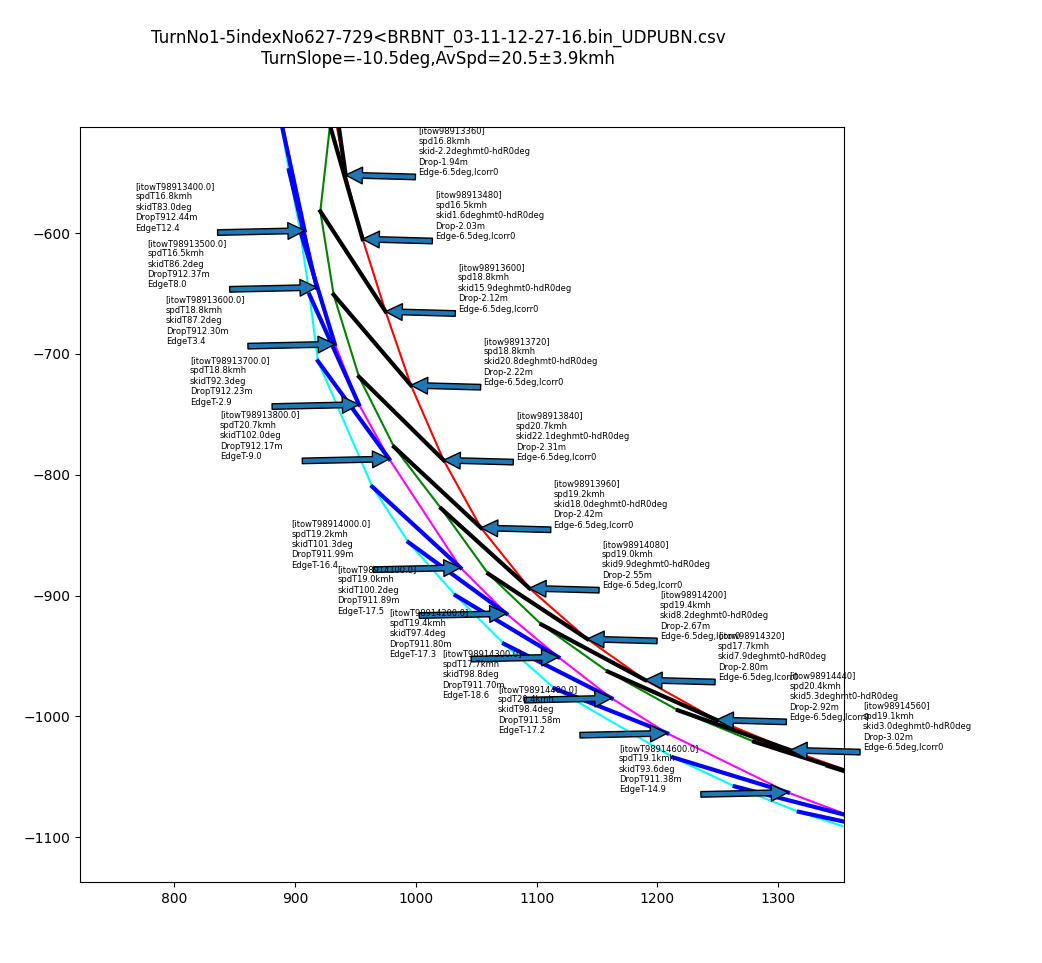
スキーターン運動の時間軸は10-100msec内で大きく動くので、100msec毎の物理量(速度ベクトル、角付け角、スキー板姿勢、落差、ターン軌跡統計)
時間毎に刻々と変化する物量とターンのTrajectory線図を同時に確認することで、どのようにスキーを操作した結果がターンになったのか理解を手伝います。
私の場合は、初心者なので、板に乗れてない滑りのデータとなってます。パラレルになっていないターンがほとんどです。
●pandas TIPS 備忘録
①行編集した後にindexをresetしておくこと(indexが歯抜けになっていた、後処理でindex番号無いとエラーになる)
|
df_Base = df_Base.reset_index() # index番号リセット
|
②列数があってないとpandas始まらない
元のデータにnull列がはいっていているがexcelでは見えないので、そのままpandasで読み込んでヘッダーをつけるとエラーになる
下記例は、7列のつもりがnull列があったので、null列を除去してからヘッダー名list_BNO0を追加している
|
if len(df_BNO.columns)>8:
df_BNO=df_BNO.drop(range(7,len(df_BNO.columns)),axis=1 )
df_BNO.columns=list_BNO0
|
③ 最終行、開始行の-1は、iloc指定
最終行を指定する-1は、iloc
|
df_BNO120.iloc[-1,0]
|
開始行と最終行を1行プリントするのはhead91) tail(1) デフォルトは5行
|
print(“df_BTBNO2:”,df_BTBNO2.head(1),”\n”,df_BTBNO2.tail(1)DFDF
|
④DF同士の横合体では行数を合わせる場合df処理でなくlistに戻してlistで行数をあわせたデータを作ってからdf=pd.DataFrame(list)にすること
行数が少ないデータを途中行から埋め込む場合、開始行から埋め込む行までゼロデータで埋める
|
list_bno = []
#listを作成してからDFに変換 list_bno = [[0] * 7] * (basestart) # 上のデータ0:basestartまでゼロ埋め
blen = len(df_BNO120)
for i in range(0, blen – 1): #df_BNO120をlistに追加
r = df_BNO120.iloc[i, :]
list_bno.append(r)
df_BNOL = pd.DataFrame(list_bno, columns=list_BNO0)
|
⑤列内のデータ検索して抽出
forループを使うより早くて1行で済む
|
df_Base = df[df.iloc[:, 0] == ‘B’]
# id列[:,0]が’B’ならばdf_Baseとして抽出
|
⑥列の一括処理 移動平均 rolling
|
# —headMot移動平均3個MA3
df[“headMotMA3”] = df[“headMot360”].rolling(3).mean()
|
⑦列の一括処理 座標間の距離計算 df.apply(lambda: )
変数が複数ある場合はrow[列名]で参照する
|
#Vaをax ayから計算代入df[‘D’] = df.apply(lambda row: row[‘A’] + row[‘B’]
df_BNO[‘Va’] = df_BNO.apply(lambda row:math.sqrt(row[‘ax’]**2+row[‘ay’]**2), axis=1)
|
⑧列の一括処理 行間で直線回帰して相関係数計算
m行のデータ間で直線回帰して相関係数を求める
XY座標で直線回帰して、相関係数がたかければ直線性が高い。
|
for i in range(m,len(df)-m):
x=[]
y=[]
for j in range(0,m-1):
x.append(df.loc[j+i,”relPosE_B”])
y.append(df.loc[j+i,”relPosN_B”])
# データを用意
# リストをps.Seriesに変換 numys seriesで処理
X=pd.Series(x)
Y=pd.Series(y)
# pandasを使用してPearson’s rを計算
res=X.corr(Y) # numpy.float64 に格納される
df.loc[i+n,”linecorr”]=res#i+n番目に代入5個なら i,i+1,[i+2],i+3,i+4
|
以後、思い出したtips追記していきます。
●STA24データシステムの備忘録
2種類のマイコンシステムのログでログ方式とフォーマットが全然違うので、通常のログシステムの何倍も複雑になってます。
●以後
STA24の目標として、MBをやめて、IMUで代替えするテーマは、スキーの要求精度が厳しい点が見えてきたので、代替えでなく
MBとIMUを併用して、より精度を上げる方向へ変更します。そのため、現在のBootsOnシステムは、使わないで、
両足MovingBaseシステムにします。5月連休までに、左足のMovingBase作成して横手渋峠スキー場で最終計測をする目標でやります。





