2週間の格闘からの学びまとめ。仕様=CSVカタログを唯一の真実にし、コードは機械的に読むだけにすると、LLMの“度忘れ”や実装ブレを構造的に潰せる。
●経緯:こんなに苦労しなくてもRTKLIBを使えばいいのですが、自作にこだわるので、ある程度自分の頭の中でなにをやっているか知りながらChatGPTに作らせることにこだわった結果2週間もかかってしまいました。将来的にGPTを活用していろいろな新規開発をしていきたいので、GPTの癖と扱い方のノウハウを開拓する意味もあります。
今回のGPTの課題;RTCM資料をPDFで渡しても、ヘッダをみつけてからの処理を延々とやっていくうちに完全に忘れて、GPTの過去学習の予測を優先してコードを組んでしまうため、途中からとんでもない仕様外れのコードを組んでしまう現象が多発しました。理由を聞くと、GNSS関係はマイナーなので、元々の学習ベースにないので、その場その場でユーザーの話しを聞きながらコードを想定しながら作っているそうで、仕様も確率的に考えているという恐ろしいことをやってました。これでは永遠にパースができないので、L6のCSSRをSSRにデコードするのは、複雑すぎてGPTでは無理だろうということで、MADOCA公式ライブラリのcssr2ssr.exeをPythonラッパーSubprocessにしてデコードしてSSRのRTCMを得ることにしました。次にRTCMのパースはGPTでやろうとして、今回の仕様を忘れる事件が発生して、対策に苦慮した上げく4人目のGPTに相談して仕様の記憶が無しでもパースできる仕様カタログ表でのパース方式で
RTCMのパースを完成させた次第です
cssrssr.exe
https://github.com/QZSS-Strategy-Office/madocalib/tree/main/bin
cssr2ssr.exeをPythonで実行する
https://gist.github.com/dj1711572002/695e3cda92005023cf444ff94cdb1832
●全体の流れ
新テーマ、RTKのドップラー積分による補間テーマで、重要なのは
衛星の精密な位置速度がないと受信アンテナとの間のドップラー速度ベクトルの速度の精度がでないので、リアルタイム系で最高精度がでるMADOCA-L6 NTRIP接続のアカウントを内閣府宇宙戦略局様へ申請して、許諾していただきました。
団体に所属してない個人での申請は初めてだそうで、いい加減なことをすると失礼になるので、確実に成果をだせるように来シーズンのスキー計測に活用できるように準備を進めてます。
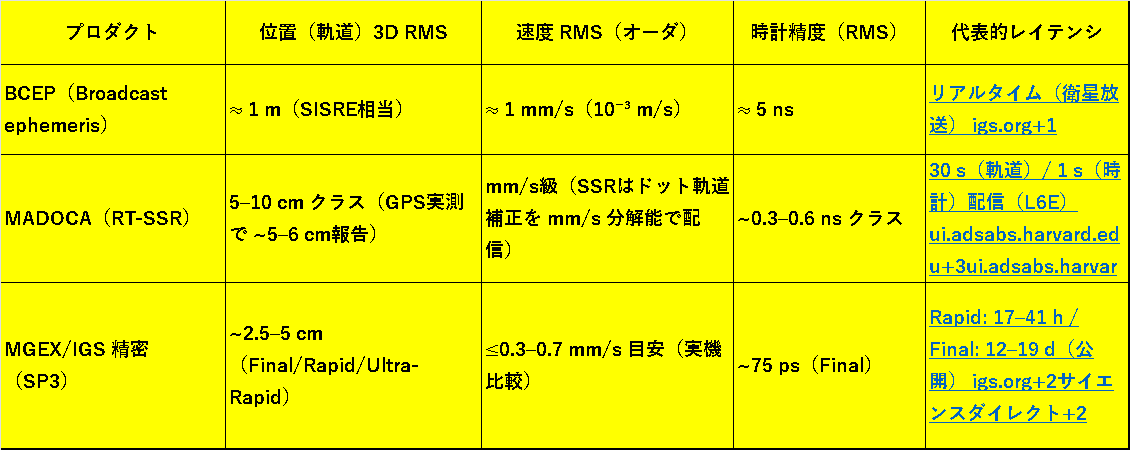
①最高精度はNASAのMGEX SP3衛星エフェメリスデータですが計測時刻から3日後に公開されるのでリアルタイムの計算にはつかえません。
②衛星エフェメリス精度をみてみると
・MGEX SP3がダントツですが3日後にしか入手できません、
・MADOCAは、JAXAが独自観測網+IGSの組み合わせで配信している補正データでリアルタイム系では精度が非常によいです、。精度的に1m以下はねらえます、
・BCEPは、通常のGPS受信機が衛星の放送として受信する放送暦ですがこれは
精度が悪くこれだけで地上の位置だと通常のGPS程度の数m誤差でます。
●処理の流れ
| STEP | アイテム | 内容 |
| 補正データログ | MADOCA NTRIP | 内閣府管理のNTRIP接続 C#【MADOCANTRIP Logger】 L6フォーマットなので、 cssr2ssr.exeでSSRに変換する 【SubProcess_cssr2ssr.py】 SSRをRTCM csvにパース 【extract_cssr_from_rtcm.py】 |
| 放送暦ログ (BCEP) |
CDDIS BCEP NTRIP | NASA CDDISのNTRIP接続 【ntrip_bcep_logger_v2.py】 RTCMをRINEX-NAV変換 【make_nav_from_rtcm3_fixed.py】 |
| MADOCA 補正適応 |
BCEP+MADOCA SSR RTCM補正 | 補正してSP3ファイルを作成しテ完成 【madoca_merge_to_sp3_v1.6.2.py】 |
回転治具でのドップラー速度積分での精度計算に使って精度確認
を行います。
①MADOCA テストライブラリ cssr2ssr.exeがあるリンク
https://qzss.go.jp/technical/dod/madoca/madoca_test-library.html
②MADOCA全般資料
https://qzss.go.jp/en/technical/ps-is-qzss/ps-is-qzss.html
③L6-CSSRフォーマット資料
https://qzss.go.jp/en/technical/ps-is-qzss/is_qzss_mdc_004_agree.html
https://ssl.tksc.jaxa.jp/madoca/public/doc/Interface_Specification_B_ja.pdf
やったこと(要約)
-
**仕様カタログ(CSV)**で各MTのフィールド順・ビット長・型を定義
message_type, field, bits, data_typeの4列だけ -
パーサはCSVを読み込んでビットを順に読むだけ(推論や“覚える”は不要)
-
RTCMフレーム抽出→カタログにあるMTは解析済みCSV、無いMTや失敗はraw CSVで必ず保存
-
**1057/1058/1062のスケール(m / m/s / m/s²)**を適用して “*_m” 列を出力
(1059の入れ子繰り返しにも機械対応) -
ファイル名に元ログのベース名+バージョンを付与して上書き回避
-
インデックスCSVで出現数と epoch 範囲を可視化
-
仕様の取り違え(1058にSRDを入れてNo. of Satellitesが倍になった)を表側修正だけで瞬時に矯正
ディレクトリと主要ファイル
-
ssr_df_catalog_madoca.csv… 仕様カタログ(正本)
https://gist.github.com/dj1711572002/c85456e17a50d30c6677204eacb3d9c7 -
bitreader.py… ビットストリーム読取り
https://gist.github.com/dj1711572002/2f1eeb36f0cc3684de144aee416662c3 -
spec_table.py… CSV→FieldDefロード
https://gist.github.com/dj1711572002/2d67af2f9797fd97f17d0867be791492 -
cssr_parser.py… 表をなぞるだけのパーサ本体
https://gist.github.com/dj1711572002/01cd7b7d184d111140162c5ee1744c2d-
「No. of Satellites」以降を衛星ブロックとして繰り返し展開
-
1059は衛星内でさらに
[Signal, Bias]×Nの入れ子に対応 -
スケール適用で “_m” / “_mps” を追加
-
-
extract_cssr_from_rtcm_v2.py… 全フレーム抽出+CSV出力(バージョン管理付き)
https://gist.github.com/dj1711572002/305e0f32fb27b63ca1a6e501f0367d6a -
-
解析済み:
<stem>_v2_MT1058.csv -
catalog外/失敗:
<stem>_v2_MT1259_raw.csv -
インデックス:
<stem>_v2_mt_index.csv(version, mt, count, mode, epoch_min, epoch_max)
-
-
(任意)
audit_catalog_vs_data.py… catalog外のMTを棚卸しする監査スクリプト
ここでの
<stem>は入力*.ssrのファイル名(拡張子抜き)。
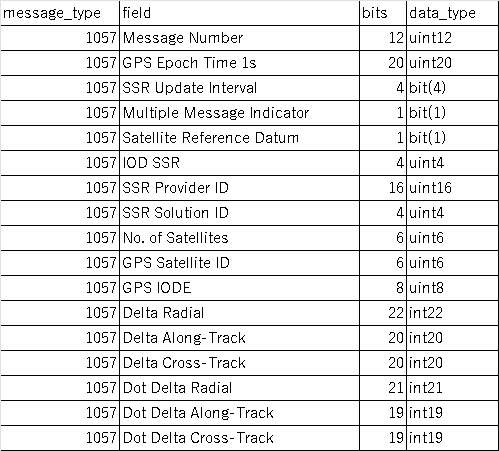
message_type field bits data_type 1057 Message Number 12 uint12 1057 GPS Epoch Time 1s 20 uint20 1057 SSR Update Interval 4 bit(4) 1057 Multiple Message Indicator 1 bit(1) 1057 Satellite Reference Datum 1 bit(1) 1057 IOD SSR 4 uint4 1057 SSR Provider ID 16 uint16 1057 SSR Solution ID 4 uint4 1057 No. of Satellites 6 uint6 1057 GPS Satellite ID 6 uint6 1057 GPS IODE 8 uint8 1057 Delta Radial 22 int22 1057 Delta Along-Track 20 int20 1057 Delta Cross-Track 20 int20 1057 Dot Delta Radial 21 int21 1057 Dot Delta Along-Track 19 int19 1057 Dot Delta Cross-Track 19 int19
-
行順=ビット並び順。これが唯一の真実
-
符号付き/無しは
data_type(例:int22,uint20,bit(4))で判定 -
「No. of Satellites」を検出したら 以降を衛星ブロックとして
n_sat回読む-
1059のように衛星内でさらに可変繰り返しがある場合は、
No. of Code Biases Processedを読んで直後の[Signal, Bias]をN回繰り返すだけ -
スケールの扱い(m / m/s / m/s²)
-
表の“名前一致”で係数を適用し、
*_m/*_mps列を追加 -
代表例(RTCM 10403.2ベース)
-
1057(軌道)
-
Delta Radial:0.0001 m/LSB(0.1 mm)
-
Delta Along/Cross:0.0004 m/LSB(0.4 mm)
-
Dot項:0.000001 / 0.000004 m/s
-
-
1058(時計)
-
C0:0.0001 m/LSB(0.1 mm)
-
C1:1e-6 m/s/LSB(適用時にΔtを掛ける)
-
C2:2e-8 m/s²/LSB(適用時にΔt²を掛ける)
-
-
1062(高レート時計)
-
0.0001 m/LSB
-
-
ブログでは “C0が1〜1.3 mでも正常、適用値は C0 + C1·Δt + C2·Δt²” と一言補足しておくと誤解が減ります。
出力設計(落とさない・上書かない・追跡できる)
-
必ずどちらかを出力
-
解析成功 →
<stem>_v2_MTxxxx.csv -
仕様外/失敗 →
<stem>_v2_MTxxxx_raw.csv(payload_hexとframe_hexを保存)
-
-
バージョン列・タグ
-
各CSVの先頭に
version列(例:v2) -
ファイル名にも
_v2_を組み込み → 将来v3と共存できる
-
-
インデックス
-
<stem>_v2_mt_index.csvにcount/mode(parsed|raw)/epoch_min,max -
indexにあるのにCSVが無いという穴を構造的に排除
-
実装の要点(コードの読み方)
-
BitReader:RTCM payload(frameの0xD3ヘッダ+len+payload+CRCのうちpayload)から先頭12bitでMT抽出
-
spec_table.load_spec:CSVを
FieldDefの配列へ。MTごとに行順を保持 -
CssrParser.parse:
-
ヘッダを順に読む
-
「No. of Satellites」以降=衛星ブロックを
n_sat回 -
1059は衛星内で
No. of Code Biases Processedを読んで[Signal, Bias]×N -
スケールがあれば
*_m/*_mpsを追加 -
余りビット(パディング)は厳密チェックしない(実装差分に強くするため)
-
-
extract_cssr_from_rtcm_v2.py:
-
CRC-24Q を検証(
VERIFY_CRC=True) -
TARGET_MESSAGE_TYPES=Noneで見つかった全MTを対象 -
既知MT→解析、未知/失敗→rawにフォールバック
-
ファイル名=
<stem>_<version>_MT<mt>.csvで上書き回避
-
トラブル事例と対処(実録)
-
1058に“Satellite Reference Datum”を入れてしまい、
No. of Satellitesが60に倍化
→ CSVを修正(1058はSRD無し)だけで復旧。コードには一切触れずに正しい列数・値へ -
MADOCA仕様と実データのズレ(1062 vs 1058)
→ データ側に1058が流れていると判明。1058をカタログに追加して即対応 -
出力ファイルが不足
→ raw出力の標準化で“取りこぼしゼロ”。indexのmodeで一目で判別
運用チェックリスト
-
ssr_df_catalog_madoca.csvが正しいか(1058にSRD無し / 1057ドット項の型 等) -
VERIFY_CRC=Trueで*_mt_index.csvの count が期待どおりか -
parsedで出るMTが増えているか(rawが残ればカタログ未整備のサイン) -
1057の
_m列が1 m未満に収束、1058の C0 が数 m以内で自然か -
バージョンを上げる時は
PARSER_VERSION/VERSION_TAGを更新し併存させる
伸びしろ(必要になったら)
-
適用後の時計補正:
Clock(t)=C0+C1·Δt+C2·Δt²をCSV列で出力 -
縦長(1衛星=1行)出力:長大列を避けたい用途向け
-
カタログに version/hash 列を追加し、実行時に乖離検出(安全運用)
-
サブフォルダ分割:
cssr_out/v2/<stem>/...(大量ログ運用)
まとめ
-
仕様を“表”に固定して、コードは表を読むだけにする——たったこれだけで、
実装ブレ/勘違い/度忘れが構造的に起きにくいパイプラインになりました。 -
解析側の変更はCSVに追記・修正するだけ。コードは安定・再現性が高い。
-
“catalog外”でも必ずrawを残す設計で、取りこぼしゼロと後追い修正を両立。
コードはGistに公開(推奨):「bitreader.py / spec_table.py / cssr_parser.py / extract_cssr_from_rtcm_v2.py / (任意)audit_catalog_vs_data.py」。
記事にはこの方針と運用の勘所だけを書けば、将来の自分の助けになります。 -
-