4月からPython初めて、RTKとIMUのデータ処理プログラム作成してきたのですが、当初のプログラムは
初心者のため、pandasの機能を十分使ってなかったり、内包処理をしてないforループが多かったりで
冗長で、遅くて、見にくいプログラムでした。
そこで、お盆休みに現在の私のpythonのレベルで、書き直しを始めてます。
●IMUの外れ値除去
10msecサンプリングで周期的にデータがつぶれている個所があります。
バイナリの抜けが発生しているみたいで、規定のデータ長がありません。
ヘッダーを目印に処理しているので、1か所ずれていてもそのエポックだけで被害が
済むようになってます。
①外れ値の種類と修復
現象A:BNO085のタイムスタンプだけが飛んでいる
10msec周期でサンプリングはきちんとしているのですが、マイコンでタイムスタンプがずれる現象。
GPSの絶対時刻iTOWと同期させてタイムスタンプを作製しているので、マイコンの調子でタイムスタンプ書き込みがエラーになっている場合が時々発生してました。
対策A=>スタートのiTOW時刻から周期10msecをrange()でインクリメントして全行埋める。
|
タイムスタンプ df[“bnitow”]を生成
df_bno[‘bnitow’] = range(startbnitow, rstop,rstep)
startbnitow=スタート時刻
rstop=最終行での時刻
step=10msec毎に増加させる
|
現象B:IMUデータyaw,pitch,roll,ax,ay,azが行全体で桁外れの値に化けてしまう。
これは、バイナリデータの書き込み抜けが発生してしまっているから全行ダメになってます。
対策B=>上下の正常なデータから平均値をとって。異常行を埋める
原理:各パラメータのdiff()とその標準偏差stdと平均値avrgを計算して、3σ内にはいる
偏差 upper=avrg+std*3 と lower=avrg-std*3 を求める。
この偏差から外れている行をDFとして抽出するErrU ,ErrL
ErrU,ErrLのindexから修復対象行と前後の行から平均値を計算して、修復行に代入する。
|
def noisecut(df):
targetcol=[“yaw”,”pitch”,”roll”,”ax”,”ay”,”az”]
difcol=[“yawdiff”,”pitchdiff”,”rolldiff”,”axdiff”,”aydiff”,”azdiff”]
for i in range(0,len(targetcol)):
tc=targetcol[i]
dc=difcol[i]
col3sigma=df[dc].std(numeric_only=True)*3
colavrg=df[dc].mean(numeric_only=True)
upper=colavrg+col3sigma
lower=colavrg-col3sigma
ErrU=df[df[dc]>upper]
ErrL=df[df[dc]<lower]
print(dc,”:upper:”,ErrU.index)
print(dc,”:lower:”,ErrL.index)
for j in range(0,len(ErrU)):#外れ値を前後行で平均埋め
Uindex=ErrU.index[j]-1
Lindex=ErrU.index[j]+1
df.loc[ErrU.index[j],:]=df.loc[[Uindex,Lindex]].mean()
for j in range(0,len(ErrL)):#外れ値を前後行で平均埋め
Uindex=ErrL.index[j]-1
Lindex=ErrL.index[j]+1
df.loc[ErrL.index[j],:]=df.loc[[Uindex,Lindex]].mean()
#print(df.loc[Uindex:Lindex,:])
df[“yawdiff”]=df[“yaw”].diff()
df[“pitchdiff”]=df[“pitch”].diff()
df[“rolldiff”]=df[“roll”].diff()
df[“axdiff”]=df[“ax”].diff()
df[“aydiff”]=df[“ay”].diff()
df[“azdiff”]=df[“az”].diff()
return df
|
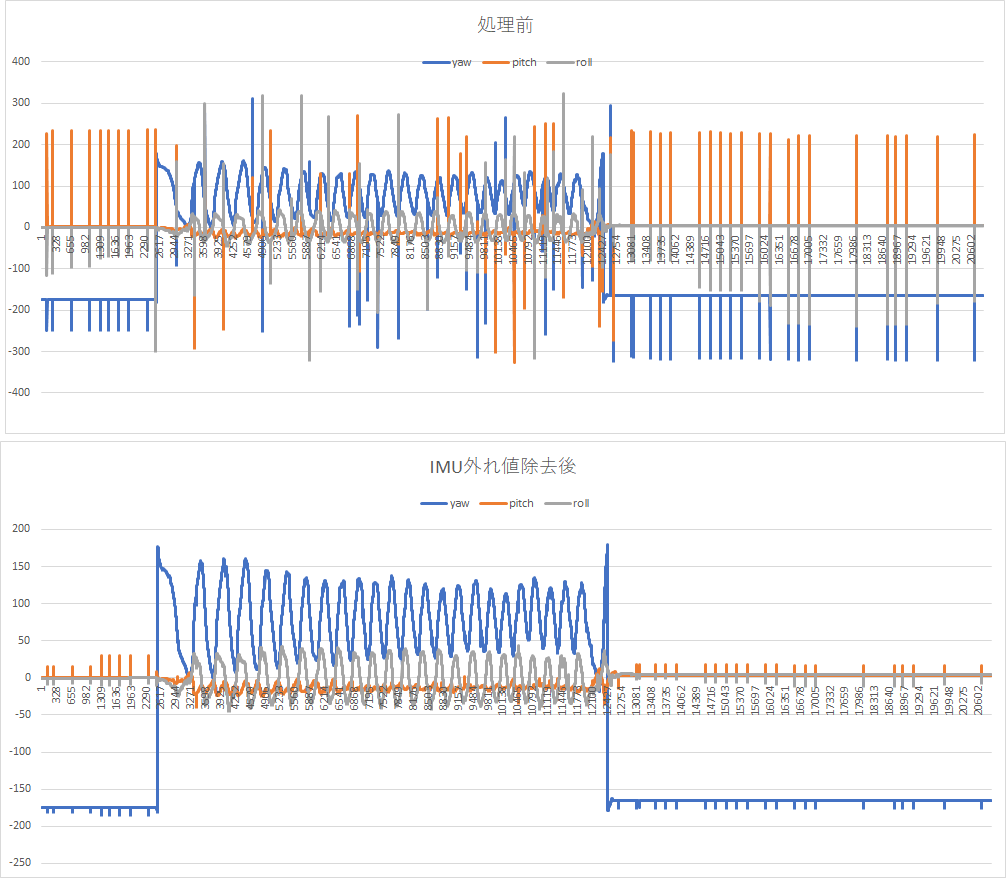
●結果
グラフでみると外れ値のピークが消えてます。
●コード https://gist.github.com/dj1711572002/30bb32707925315c085a8b8b415f3b6d
●今回から作った関数は、myFというライブラリーに収納してmainのプログラムをシンプルにしました。
やりかたは簡単で、myFというファイルに関数群をコピペしておいて、mainと同じフォルダーに置いておく
main のプログラムに import myF と宣言しておく。
関数を使うときは、 myF.関数名() とすれば、通常の関数と同じく使えます。