前回初めてPythonでナイナリーをいじるのにbyte型、bytearray型を使って、ハマってしまったのですが、
更に、調べるとnumpyで扱ったほうがシンプルで悩む必要がないことがわかりました。
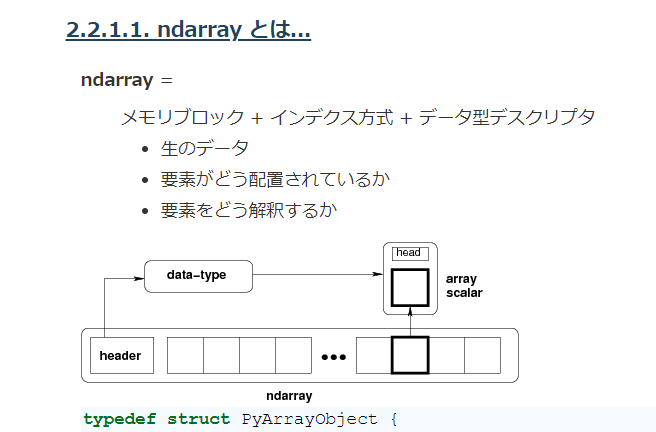
Cに慣れている人は、numpy ndarrayでバイナリーを扱うとCライクに扱えるので楽です。
見出しのページは、numpy配列の詳細な解説ページです。感謝です。
http://www.turbare.net/transl/scipy-lecture-notes/advanced/advanced_numpy/index.html
●参考にさせていただいた記事に感謝
私も組込み系の技術者に近いので、組込みエンジニアの戸惑い様には同感する点多いです。
①組み込みエンジニアの戸惑い 様
https://www.fsi-embedded.jp/kumico/column/837/
https://www.fsi-embedded.jp/kumico/column/1204/
②note.nkmk.me 様 感謝
numpy 配列(numpy ndarray とかnumpy arrayと呼ばれてます)
https://note.nkmk.me/python-numpy-dtype-astype/
umPyの主要なデータ型dtypeは以下の通り。整数、浮動小数点数のそれぞれの型が取り得る値の範囲については後述。
データ型dtype |
型コード | 説明 |
|---|---|---|
int8 |
i1 |
符号あり8ビット整数型 |
int16 |
i2 |
符号あり16ビット整数型 |
int32 |
i4 |
符号あり32ビット整数型 |
int64 |
i8 |
符号あり64ビット整数型 |
uint8 |
u1 |
符号なし8ビット整数型 |
uint16 |
u2 |
符号なし16ビット整数型 |
uint32 |
u4 |
符号なし32ビット整数型 |
uint64 |
u8 |
符号なし64ビット整数型 |
float16 |
f2 |
半精度浮動小数点型(符号部1ビット、指数部5ビット、仮数部10ビット) |
float32 |
f4 |
単精度浮動小数点型(符号部1ビット、指数部8ビット、仮数部23ビット) |
float64 |
f8 |
倍精度浮動小数点型(符号部1ビット、指数部11ビット、仮数部52ビット) |
float128 |
f16 |
四倍精度浮動小数点型(符号部1ビット、指数部15ビット、仮数部112ビット) |
complex64 |
c8 |
複素数(実部・虚部がそれぞれfloat32) |
complex128 |
c16 |
複素数(実部・虚部がそれぞれfloat64) |
complex256 |
c32 |
複素数(実部・虚部がそれぞれfloat128) |
bool |
? |
ブール型(True or False) |
unicode |
U |
Unicode文字列 |
object |
O |
Pythonオブジェクト型 |
データ型名の末尾の数字はビット(bit)で表し、型コード末尾の数字はバイト(Byte)で表す。同じ型でも値が違うので注意。
③Scipy lecture NOTE 様感謝
2.2. Numpy の先進的な機能
http://www.turbare.net/transl/scipy-lecture-notes/advanced/advanced_numpy/index.html
●バイナリファイルを読み込んだ時の比較
①bytearray型で読み込む
スライスをprintすると訳の分からない記号が16進文字に混ざって出力されて、訳が分からないので困る。
元データは、16進数でB5 62 01 07 5C 00 38 D3 52 1Aですが、07以降が化けていて見えません、普通にprintでは正確に数値を確認することができない型では困ります。
|
f = Path(filename)
size = f.stat().st_size
#====== READ Binary FILE======= bd=bytearray(size)
f = open(filename, ‘rb’)
bd=f.read()#bd配列に収納
f.close()
print(bd[0:10])
print(type(bd))
|
| 上記コードの出力
>>>>>>READ FILE; C:/UPload/3-15-11-40.ubx |
②numpy で読み込む
printした結果が数値そのもので、byte型のように訳のわからない記号がつかないのが良い。
B5 62 01 07 5C 00 38 D3 52 1A 出力は10進ですが、正確にでてます。
|
bd = np.fromfile( filename, dtype=np.uint8 )
print(bd[0:10])
print(bd.dtype)
|
| 上記コードの出力 >>>>>>READ FILE; C:/UPload/3-15-11-40.ubx [181 98 1 7 92 0 56 211 82 26] uint8 |
読み込み速度は、600kByteのバイナリファイルでは、ほとんど瞬時で読み込めました。
しかし、PRINTしたら化け文字になってしまうbytearray型では、扱いが困ります。
●4バイトをINT32へ変換
①bytearray型を使った場合は、ASCIIデータなので、計算ができる形にパックする必要があります。
|
def Toint32(d4,d3,d2,d1):
packed=pack(“>BBBB”,d4,d3,d2,d1)#pythonのバイナリ書式文字列に変換
#print(packed)
ibig=int.from_bytes(packed,’big’,signed=True)
return ibig
|
②numpy配列の場合は、数値として普通に処理すればよいです。
参考にさせていただいたサイトに感謝
numpyでシフト演算を使って符号無し⇒符号有りに変換する
シフト演算で4バイトを符号無しINT32に変換する関数を作る、これは、汎用的なので、すぐ判る。
|
def shift4(d3,d2,d1,d0):
i0=d0
i1=d1<<8
i2=d2<<16
i3=d3<<24
i=i0+i1+i2+i3
print(i0,i1,i2,i3,”=”,i)
return i
|
これをメインで使うと
|
#shift
lon=shift4(bd[33],bd[32],bd[31],bd[30])
print(lon)
|
| 上記コードの出力
166 35584 8323072 1375731712 = 1384090534 経度がでました。 |
●以後
C#より、演算速度は、遅いですが、数Mバイト程度のファイルなら、あまり待つことなく処理できそうなので
バイナリファイルの処理もPython numpy ndarrayを使っていく方針でいきます。