Python始めて4か月でcsvファイルばかり扱ってきたのですが、STAシステムは、ublox F9Pからバイナリのデータが大量に吐き出されてきます。Teensy4.1の超高速SD書き込みでやっとこ保存して、PCへは、USB2.0で17Mbpsで取り込むところまでは、C++とC#で処理してきたのですが、データの加工性を考えると後の処理は。Pythonが良いだろうということで、大量にあるバイナリーファイルからublox ubxフォーマットの実数に変換処理することを始めました。
結論=>バイナリーは、C#で数値型に変換してASCIIにして、Pythonに渡すほうが合理的なので、
pythonでバイナリー変換するプログラム作り途中で断念しました。Pythonは、C#が吐き出した雑多なファイル群を
きれいに整理整頓、統計処理するのが得意な言語ですので、両者の長所を組み合わせるのがコスパが良いです。
●C#と違うと感じた点
=>バイト型を扱うとPythonコードは長くなるC#の3倍くらい長くなる、当然変換スピードもC#のほうが速いはず
=>巨大なバイナリーファイルを扱う場合は、C#でバイト処理をして、ASCIIで数値を表現できるようにしてから
Pythonに渡すほうが合理的だと感じた。
●Python.orgのバイト型変数の扱いを下記で説明してます
https://docs.python.org/ja/3/library/stdtypes.html#binary-sequence-types-bytes-bytearray-memoryview
ここで、大きな相違は、下記解説です。
| bytes はバイトの不変なシーケンスです。多くのメジャーなプロトコルがASCIIテキストエンコーディングをベースにしているので、 bytes オブジェクトは ASCII 互換のデータに対してのみ動作する幾つかのメソッドを提供していて、文字列オブジェクトと他の多くの点で近いです。 |
なんとBYTE型だけど、ASCIIで表現するのがPythonの世界らしいです。確かに、あらゆる基準がASCII文字データが基準ですべてのライブラリーがあるので、バイナリを使うことは滅多にありませんので、
バイナリだけ、数値で表現しても仲間外れにされてしまうということらしいです。
しかし、大きなバイナリーのバッファを扱うライブラリーあるようです。https://docs.python.org/ja/3/c-api/buffer.html#bufferobjects
Pythonで利用可能ないくつかのオブジェクトは、下層にあるメモリ配列または buffer へのアクセスを提供します。このようなオブジェクトとして、組み込みの bytes や bytearray 、 array.array のようないくつかの拡張型が挙げられます。サードバーティのライブラリは画像処理や数値解析のような特別な目的のために、それら自身の型を定義することができます。
| Python | C# | |||||
| バイトの型表現 | 組み込み型として特別扱いの型 バイトオブジェクト bytes リテラルでは (ソースコードのエンコーディングに関係なく) ASCII文字のみが許可されています。 127より大きい値を bytes リテラルに記述する場合は適切なエスケープシーケンスを書く必要があります。 =>bytesリテラルという単語の如く 文字列型みたいに、フォーマットでバイトの型を表現しないといけないというルールになっている 例えば int32 を表す 4バイトのd4,d3,d2,d1からint32を得るには、 自分で、下記関数を作って取得します。 使うライブラリは、struct のpack from struct import *
def Toint32(d4,d3,d2,d1):#BIG順
#pythonのバイナリ書式文字列に変換
packed=pack(“>BBBB”,d4,d3,d2,d1)
#書式変換したpackedで、byte=>int変換
ibig=int.from_bytes(packed,’big’,signed=True)
return ibig
フォーマットの”>BBBB”がバイト型を決めてます。
|
メモリー上の物理的な値 byte型 char型 uint8_t型
//便利なのは、(buf,index)とindexは、データ配列のスタート位置です。巨大なバイト配列が普通なので、index変数として、次々と4バイトずつループしてint32変換を行えます。 |
|
1 |
<strong><span style="font-size: 14pt;">●pythonのstructライブラリのバイナリフォーマットを調べて、使う必要があります。</span></strong> |
struct — バイト列をパックされたバイナリデータとして解釈する
https://docs.python.org/ja/3/library/struct.html
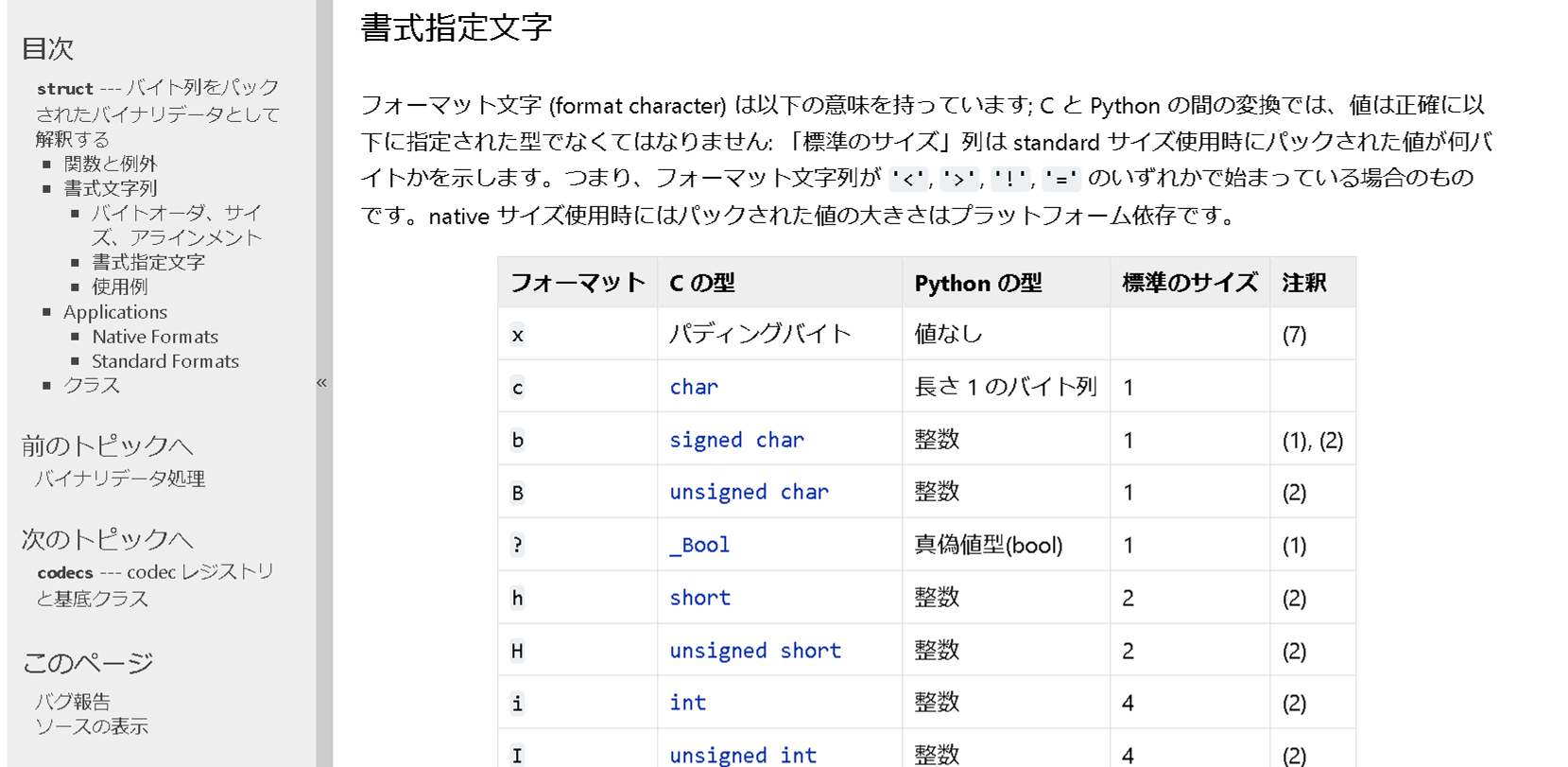
書式指定文字
フォーマット文字 (format character) は以下の意味を持っています; C と Python の間の変換では、値は正確に以下に指定された型でなくてはなりません: 「標準のサイズ」列は standard サイズ使用時にパックされた値が何バイトかを示します。つまり、フォーマット文字列が '<', '>', '!', '=' のいずれかで始まっている場合のものです。native サイズ使用時にはパックされた値の大きさはプラットフォーム依存です。
| フォーマット | C の型 | Python の型 | 標準のサイズ | 注釈 |
|---|---|---|---|---|
x |
パディングバイト | 値なし | (7) | |
c |
char | 長さ 1 のバイト列 | 1 | |
b |
signed char | 整数 | 1 | (1), (2) |
B |
unsigned char | 整数 | 1 | (2) |
? |
_Bool | 真偽値型(bool) | 1 | (1) |
h |
short | 整数 | 2 | (2) |
H |
unsigned short | 整数 | 2 | (2) |
i |
int | 整数 | 4 | (2) |
I |
unsigned int | 整数 | 4 | (2) |
l |
long | 整数 | 4 | (2) |
L |
unsigned long | 整数 | 4 | (2) |
q |
long long | 整数 | 8 | (2) |
Q |
unsigned long long | 整数 | 8 | (2) |
n |
ssize_t |
整数 | (3) | |
N |
size_t |
整数 | (3) | |
e |
(6) | 浮動小数点数 | 2 | (4) |
f |
float | 浮動小数点数 | 4 | (4) |
d |
double | 浮動小数点数 | 8 | (4) |
s |
char[] | bytes | (9) | |
p |
char[] | bytes | (8) | |
P |
void* | 整数 | (5) |