
スキー場でSTA24システム計測実験が軌道にのってきて大量のデータがログできたのですが、あまりにも処理が大変で、Excelでは無理なのでPythonでやるのががSTA24の春からの目標となってます。
●最初にはまった点
①RTKデータの欠番を埋めるやり方がわからない
VB,C#のDataGridなら、Insert コマンド一発で行を途中で挿入できるのですが、
pandas DataFrameのInsertは、列挿入にしか使えませんでした。行挿入の便利コマンドはありませんでした。下記LINKを見ると 使うとしたら3種類の選択があるそうです。
https://note.nkmk.me/python-pandas-assign-append/
しかし、append命令は、非推奨で使うなということで、困ってしまいました。
慣れた人ならほいほいと出来るのでしょうが、初めてだと、あちこちで不具合があるので
エラーが出たら最後で、どこが原因か突き止めることができません。
そこで、エラーが出ない方法を試行錯誤で探しました。
作戦1:挿入したい行データをまとめてDFの下端に追加して、1本のDFでSORTでそろえる。
作戦2:DFで、操作listで全データを作って、新たなDFを作成してから、SORTさせる。
この方法が速いという記事があって、感謝しております。
http://taustation.com/pandas-dataframe-appending-speed/#loc
DataFrameのスピード~行の追加
このページで既存のDFに行を追加する方法で高速なやり方をご紹介されてました。
まずは、サンプルプログラムがあるので、コピペして走らせると1万行が一瞬で追加できました。
これならいいということで、このやり方を真似させていただきました。
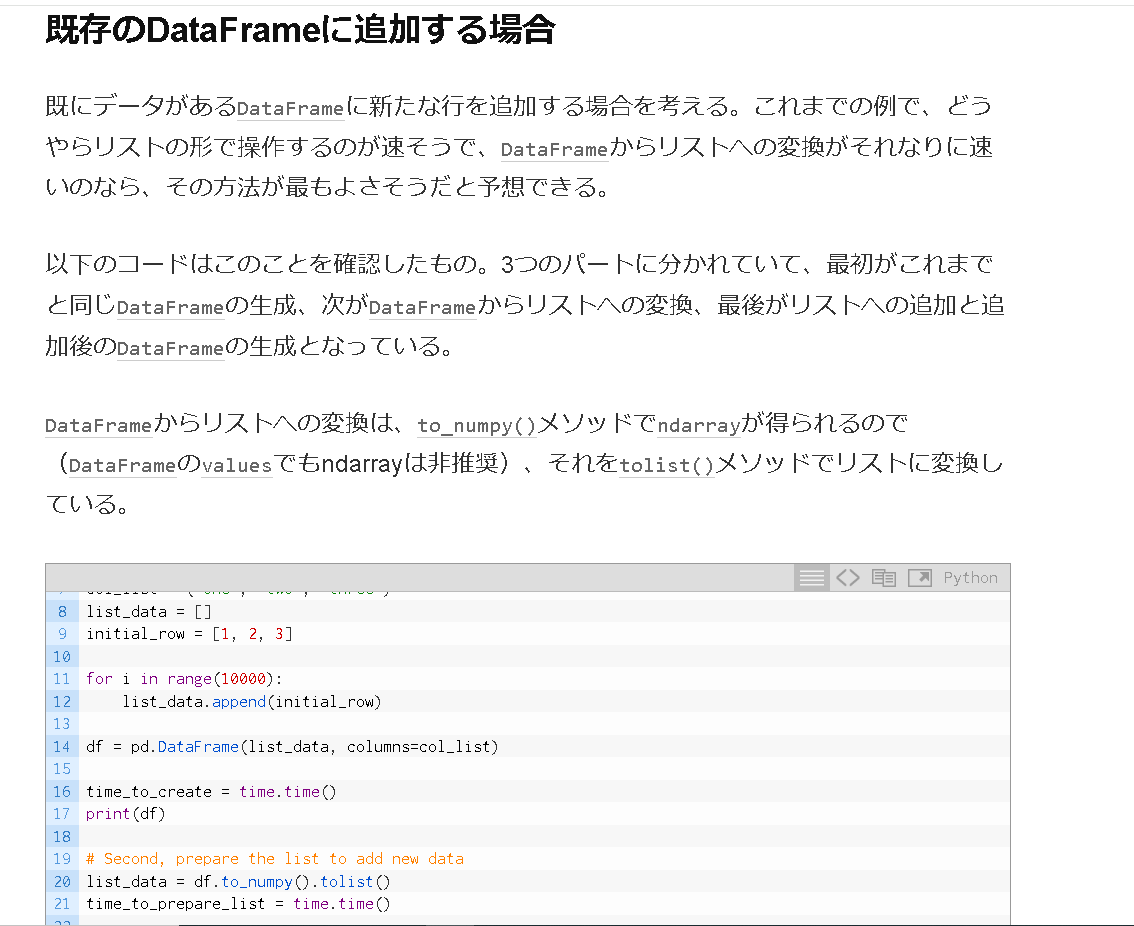
1)既存のDFからlistを作成 list_data=[]
2)listに既存の全DFデータをコピー list_data = df_Base.to_numpy().tolist()
3)挿入したいlistを作成 c=[]
4)挿入したいlistの1行分データ作成 for i in range(0,N):
c.append(data[i])
5)1行分list cができたら母艦list_dataに追加 list_data.append(c)
6)所望の行数だけ、list_dataに追加したら、終了して次のステップ
7)list_dataから新たなDFを作成 df_Basew2= pd.DataFrame(list_data, columns=headB)
やり方8:sortして、挿入した行を正規の順番に配置替え df_Base2=df_Base2.sort_values(“iTOW_B”,ascending = True)
GISTに私のつくりかけのプログラム載せてありますが、専用CSVがないと動きません
https://gist.github.com/dj1711572002/4a826a4706b18ea091faafc51ccd72f4
●以後
pands DFは、使い方に慣れれば、すごく生産性があがることが判ってきたので、慣れるまで数か月かける意義はあると思います。





