※機械学習の初歩段階なので、本記事役に立つものではありませんが、将来的には、IMUの精度がでない課題を機械学習で改善できるようになりたいという希望はもってます。現在は、フィルター処理でIMUの精度を高めてますが、それだけでは限界があって、困っているわけですから、機械学習でフィルター処理のエラーをカバーするような経験を積ませればいいのではないかと勝手に想像してます。
IMUを機械学習させる実験で、
現在の特徴量は、IMUのGravityAccx,y,zの3個だけで静止の場合は100%正答率がでます。
しかし、振ったりして動かすと、50%近くまで落ちてしまうので、賢くない機械学習になってしまいました。
静止状態の姿勢なら、正解率100%近くで判別できるのですが、動かすと、50-60%まで正解率が落ちるという結果です。
これでは、ちっとも賢くないので、feature(特徴量)をどうすべきか、IMUを使った事例を調べたら下記論文にあたりました。
●スマホIMUで人間の行動を識別する研究論文
Multi-stage activity intereface for locomotion and transportation analytics
of mobile users
2018年10月の奈良先端科学大学院大学の研究でした。
人の行動で、静止、歩行、ラン、自転車、自動車、バス、列車、地下鉄
を区別する機械学習のテーマです。センサは、9軸IMUの6種出力と気圧センサの7種類の生データを特徴量に処理して、機械学習アルゴリズムを3種類で評価した論文です。
ここで使っている特徴量を参考にさせていただきました。
時間軸系の統計値 Max, Min, Mean ,Standard deviation ,Interquartile range ,Kurtosis,Variance の7個です。

●やり方
1:トレーニング(機械学習モデルを作る)
①データ測定:IMUからLinearAccx,y,zを3クラス(3方向の往復動作)の動作をしてサンプリングして imu.csv ファイルに保存して次に渡す。
②特徴量作成:統計計算して7個のパラメータを特徴量として行列を作って、 stat_darrs.csv ファイルで保存して次に渡す。
③機械学習モデル作成:scikit-learnのSVCでfitさせて、機械学習データファイル model.savを保存
2:テスト(実際にIMUを振って機械学習させた結果と合っているかテスト)
①試行:MUを任意の方向へ振ってサンプリングしたデータを imu.csv ファイルに保存して次に渡す。
②特徴量作成:統計計算して7個のパラメータを特徴量として行列を作って、 stat_darrs.csv ファイルで保存して次に渡す。
③予測:predictへ特徴量を渡して、予測結果を得る。クラス番号がでるので、どの方向に振ったかあたっているかテストする
●統計量7個での結果
https://gist.github.com/dj1711572002/53d9e6105f29c2a6604cc49320a07daa
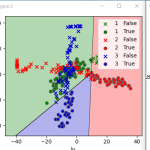
特徴量が21個もあるので、自動でグラフが書けないので、自分でExcelでとトレーニングデータのグラフを書いてみました。
3本のクラス(1がX軸方向振り、2がY軸方向振り、3がZ軸方向振り)で区別が一番つきやすいのは、分散のvar_x.var_y,var_zでした。標準偏差stdの2乗なので値が大きく差が見からです。
この21個の特徴量でのトレーニングデータを機械学習した結果は、正答率100%のテスト結果でOKでした。

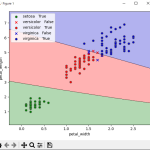
●分散に絞ったプログラムにして、グラフをだした結果
https://gist.github.com/dj1711572002/3a254e362e5e589c1089a007a3bb565a
①トレーニング
分散1個のデータなので、点が真ん中にあるだけで、アルゴリズムが適当に境界線を引いてくれます。人力ではなかなかできないです。
この学習MODELでテストをすると上記21個特徴量と同様に正答率100%でしたので、分散が一番強い特徴量だとわかりました。
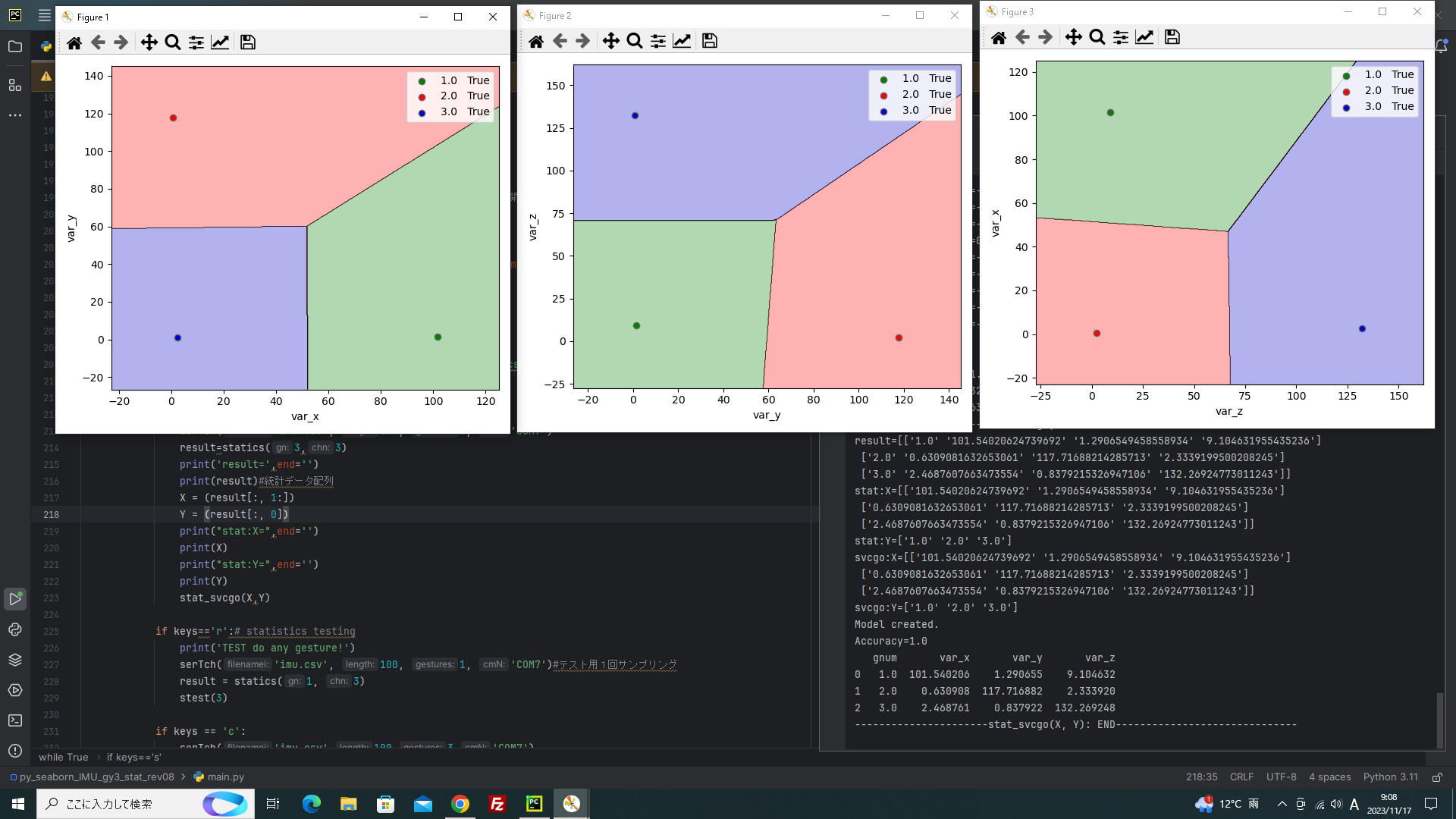
②テスト結果 1,2,3と振った方向で判別して正答を返してくれました。
| ———————-statics(gn,chn): END—————————— df= gnum var_X var_y var_z 0 1.0 92.639563 5.531745 8.346046 df1= var_X var_y var_z 0 92.639563 5.531745 8.346046 darr1=[[92.6395631 5.53174481 8.3460459 ]] tdarrs=[0. 0. 0. 0.] tdarrstr=[‘0.0’ ‘0.0’ ‘0.0’ ‘0.0’] =================Test Input MODE================ ********************This gesture is No. [‘1.0’]———————-statics(gn,chn): END—————————— df= gnum var_X var_y var_z 0 1.0 1.545021 68.447783 1.864353 df1= var_X var_y var_z 0 1.545021 68.447783 1.864353 darr1=[[ 1.54502054 68.44778285 1.86435261]] tdarrs=[0. 0. 0. 0.] tdarrstr=[‘0.0’ ‘0.0’ ‘0.0’ ‘0.0’] =================Test Input MODE================ ********************This gesture is No. [‘2.0’]———————-statics(gn,chn): END—————————— df= gnum var_X var_y var_z 0 1.0 5.167056 1.952147 132.17658 df1= var_X var_y var_z 0 5.167056 1.952147 132.17658 darr1=[[ 5.16705581 1.95214712 132.17658031]] tdarrs=[0. 0. 0. 0.] tdarrstr=[‘0.0’ ‘0.0’ ‘0.0’ ‘0.0’] =================Test Input MODE================ ********************This gesture is No. [‘3.0’] |
●プログラムの備忘録
特徴量7個:https://gist.github.com/dj1711572002/53d9e6105f29c2a6604cc49320a07daa
分散のみ:https://gist.github.com/dj1711572002/3a254e362e5e589c1089a007a3bb565a
メモ1:scikit-leranに渡す行列のデータの型は、strでもfloatでもよいみたいでした。ただし、2次元の行列でないといけないので、1行のデータでも[[ 1,2,3]]と二重カッコに加工しないといけません。
#darr1=[[ 5.16705581 1.95214712 132.17658031]] |
統計処理したデータファイルstat_darrs.csvをpandas データフレームdf として読み込んでから、scikit-learnに渡すためには、numpyの行列に変換しないといけませんので、
●感想
IMUのパラメータを追加して統計処理して、EXCERLで特徴量を眺めながら、どの動作には、どの特徴量が良いか、確認してながら、特徴量エンジニアリングをすることが重要なことがわかりました。
特徴量エンジニアリング
●以後
自分の動作をサンプリングしながら、特徴量を調べて、どの動作にはどういう特徴量が良いのか、収集してみます。スキーでも歩行でもいろいろな動作を収集すると面白そうです。
IMU以外でもRTKにも使えるはずなので、スキーターンの種類を区別することはできるとおもいます。下手くそなパラレルとか区別はつけられるはずです。
BIGデータの世界にSTA24から踏みいれることになります。