SVM決定境界線プロットとSVMのAccuracyをみると、元データ(教師となるトレーニングデータ)を何にするかが原因であったことが判りました。フタをあければ、当たり前ですが、XYZの加速度成分を分類するのに、XYZが同時に動く振り方(ジェスチャー)をしているのでそれぞれのジェスチャー内に重複するデータが多数発生するのが、分類ミスが多発する原因でした。
●元のトレーニングデータ(教師となるデータ)
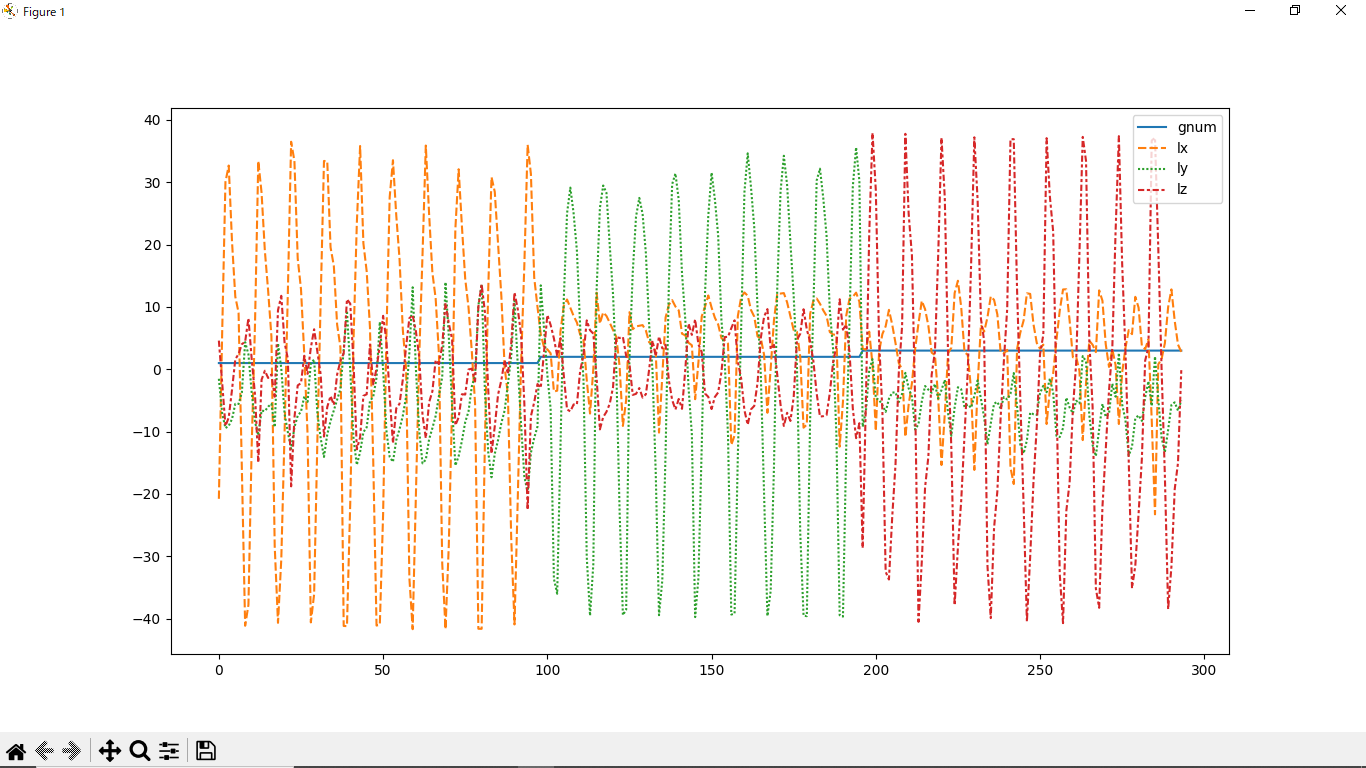
BNO055のLinearAcc(laX,laY,laZ)を採用したのですが、Linearだと重力加速度は除外しているので、姿勢差がでません。下記生データ時系列図では、左からX方向往復振り、中央がY方向往復振り、右がZ方向往復振りです。
それぞれの方向の波形が大きなピークをだしてますが、低い値では他の成分も加速が入ってしまってます。
ですので、テストデータが低い値の場合は、どの振り回し方だか分類がつかないでミスが発生します。
●機械学習の評価指標でみると
SVM分類のトレーニングデータの正解率(Accuracy)69.4%しかでてませんでした。
F1値(F値は対照的な特徴を持つ適合率と再現率の調和平均)が69.9%でした。
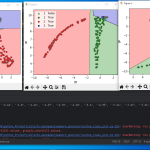
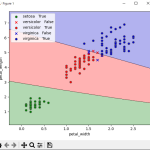
●境界線グラフ(seaborn-analyzer使用)
左図:縦laY-横laX 中図:縦laZ-横laY 右図:縦laX-laZ
入り混じっているので正解率が69%なのは納得です。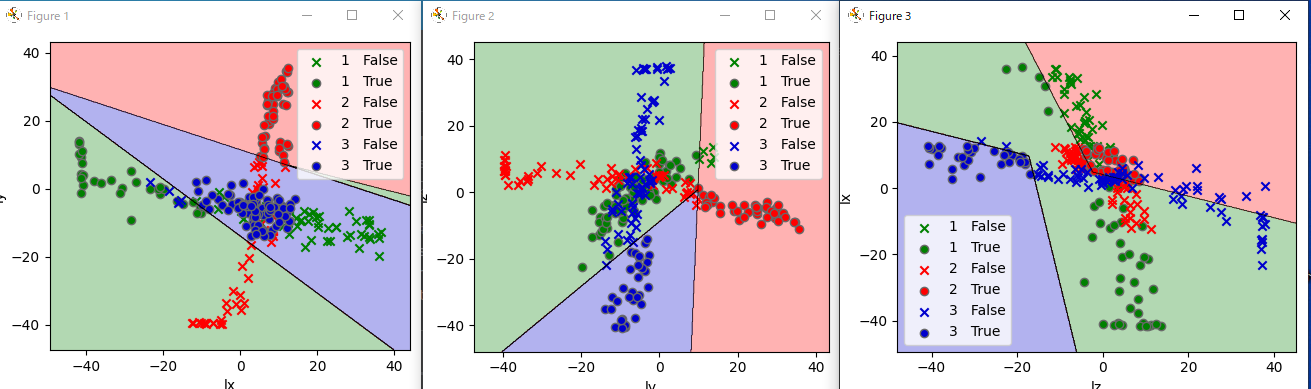
●元々の原作者の意図
魔法の杖のジェスチャーを機械学習で判定させてみた
の作者の振り回し方は姿勢を変えながらトレーニングデータをサンプリングさせていたのだと思います。
ですので、私がLinear加速度を使ったら、姿勢がでないので、SVMで分類できないトレーニングデータであっ
ということです。 Gravity加速度で、与えるか一般の加速度でトレーニングしたほうが、正解率はあがるはずです。
●IMUを使った機械学習の論文調査
剣道の技をIMUを複数個身体にとりつけて、つき技を分類した論文がありました。
剣道上達支援のためのIMUを用いた打突動作
ここでは、技毎に統計値を目いっぱいとって、機械学習のアルゴリズムを試してますが、一番良い正解率が
Randum Forestで94%でした。特徴量として、統計値 時間、周波数でとってます。
この論文の引用文献でさかのぼって、人間の行動をスマホIMUで判ありました。
有料と無料のダウンロードがありますが、無料でもダウンロードできます。
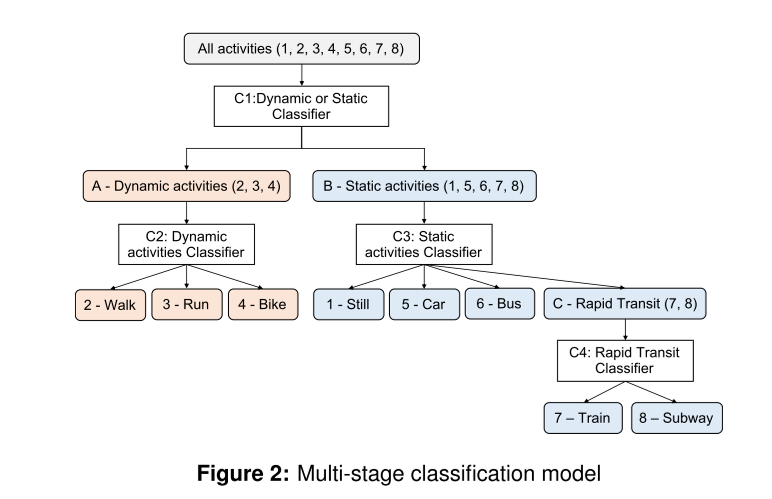
Multi-stage activity inference for locomotion and transportation analytics of mobile users
ここで使っているデータと特徴量のテーブルだけ抜粋しました。

結果として 下記のツリーで分類ができるようです。
●私のやりたいこと
時系列グラフだけみて、どんな動作をしているかは、人間の目でも難しいので、上記論文のやり方を学習して
IMUの新しい使い方をやってみたいと思います。
●プログラムの備忘録
元プログラムは、IMUからのデータをリストにアペンドしながらトレーニングデータを作成してますが、
csvファイルから読みとって scikit-learn用にデータを変換する方法でプログラムを作り直しました。
|
①IMUサンプリング
IMUのサンプリング関数でジェスチャー毎にサンプリングして、CSVファイルに保存する。
gnum,lax,lay,laz の4列を1行とするCSVファイルgnumがジェスチャー番号で
3つのジェスチャーを一つのCSVファイルimu.csvに収納します。
| 1 | -8.79 | 5.02 | -3.01 |
| 1 | 3.13 | 4.37 | -1.12 |
| 1 | 13.53 | 3.21 | -0.52 |
| 1 | 33.54 | -4.75 | 4.99 |
| 1 | 35.86 | -10.85 | 4.63 |
| 1 | 16.28 | 0.78 | 0.22 |
| 1 | 1.61 | 6.81 | 5.1 |
| 1 | -22.05 | 12.4 | 1.87 |
②scikit-leanトレーニングデータへのCSVデータ変換
scikit-learnは、pandasのデータフレームは受け入れてくれませんので、
行列フォーマットに変換しないといけません。
arr = df.to_numpy() #ここで、pandas DataFrameからnumpyの行列データ arrに変換しました。
| CSVからpandas DataFrame dfへ | 変換 | numpy の行列データarr |
| gnum lx ly lz 0 1 -2.39 -3.48 -1.57 1 1 -6.91 -2.71 -1.95 2 1 -28.57 2.07 -4.87 3 1 -27.46 3.36 -3.93 4 1 -22.68 1.74 -3.15 |
df.to_numpy() | [[ 1. -2.39 -3.48 -1.57] [ 1. -6.91 -2.71 -1.95] [ 1. -28.57 2.07 -4.87] … [ 3. 5.08 -1.25 6.16] [ 3. 3.02 -0.98 2.22] [ 3. 1.61 -0.44 -7.39]] |
データ行列とラベル行列にarrをスライスします。
X=arr[:,1:]
| X=[[-2.390e+00 -3.480e+00 -1.570e+00] [-6.910e+00 -2.710e+00 -1.950e+00] [-2.857e+01 2.070e+00 -4.870e+00] [-2.746e+01 3.360e+00 -3.930e+00] [-2.268e+01 1.740e+00 -3.150e+00] [-9.850e+00 -1.540e+00 -6.100e-01] |
Y=arr[:,0]
| Y=[1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 1. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 2. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3. 3.] |
●トレーニングデータX YをSVMにいれてFITTING
model = SVC(kernel = ‘linear’, C=1, gamma=1) #学習モデルのパラメータを指定
#model.fit(X,np.ravel(Y)) #学習を行う
model.fit(X, Y) # 学習を行う
●感想
判らなかったのは、トレーニングデータの加工方法で、WEB上では、既成データセットを使っている事例が多く
一からデータを作るやり方が少ないので、わからないままいたので、SVMのデータ入力エラーが多発しました。
要するに、scikit-leranは、行列データしか受け入れてくれないので、行列データをnumpyで作成する以外に方法が
無いということがどこにも書いてなくて、さまよい続けました。ここのサイト様に感謝です。
CSVファイルをpandasで読み込み、scikit-learnで学習させる
https://kakedashi-engineer.appspot.com/2020/03/21/pandas-sklearn/?utm_source=pocket_saves
●以後
IMUのlinear加速度でのピーク判別視点で、トレーニングデータを作成して、学習させてみます。
正解率98%以上でないと、機械学習の効果が感じられないので、粘ってみます。